 308
308
 0
0
 2023-06-19
2023-06-19
 2023-06-19
2023-06-19
本篇学习报告来自期刊"ieee transactions on instrumentation and measurement"于2021年3月刊登的论文《performance enhancement of p300 detection by multiscale-cnn》。
文章提出了一种多尺度卷积神经网络(ms-cnn)模型来检测低重复次数下的p300脑电。多尺度核在其他领域中表现出了良好的性能,如驾驶疲劳检测、精神分类症识别和癫痫eeg分类。与之前的研究相比,ms-cnn中的多卷积核可以提取不同尺度和不同时间点的特征,以捕获eeg中包含的更完整的信息。因此,这可能抵消重复减少的负面影响,以在检测精度和检测所需时间之间取得良好的平衡。该模型在2019年世界机器人大会的脑机接口控制机器人竞赛中获得了基于p300的脑机接口竞赛冠军。
实验中使用6×6的字符矩阵作为刺激界面,矩阵中的行和列会随机进行175ms闪烁,在一共12次的行或列闪烁中有两次包含了目标字符(目标所在的行和列各一次)。
实验数据集分为非特定被试和特定被试两组。其中非特定被试的数据用于非特定被试的通用模型,其中训练集有6个被试的实验数据,每个被试进行了50个sessions的实验,每个session中包含5个字符;测试集有2个sessions,每个session包含5个字符。特定被试用于特定被试的模型,包含了4个被试的实验数据,训练集有包含每个被试的1次包含5个字符的session,测试集有包含每个被试的2次包含5个字符的sessions。
原本的目标和非目标刺激的样本为1000(2×500):5000(10×500),通过对n(n=2,3,4,5,6)个原始样本进行平均从而获得新样本,使目标刺激和非目标刺激的样本数为5000:5000。
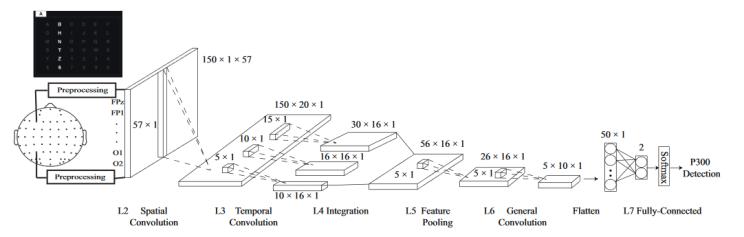
ms-cnn包括7层,分别记为l1~l7:
l1:输入层,输入eeg信号(150×1×57)
l2:空间卷积层,由大小为57等于电极的数量 的卷积核组成。卷积核的通道数为20。处理过程包括加权叠加平均(weighted superposition averaging)和共空间滤波(common spatial filtering),来提高信号的信噪比同时去除冗余的空间信息。
l3:时间卷积层,使用通道数为16的三个不同大小的卷积核[(5,1),(10,1),(15,1)],从而提取多样化的时间信息。
l4:集成层,由l3得到的三个特征图组合,用于集成提取特征。
l5:特征池化层,通过合并操作,筛选l4中获得的特征,并选择突出的特征。有助于减少计算的复杂性,并在少量训练样本的情况下防止过拟合。
l6:一般卷积层,包括一个大小为(5,1),通道数为10的卷积核。用于提取更抽象、更深和更有用的特征。
l7:全连接层,将由l6得到的特征图转换成1×50的向量。
模型中使用交叉熵损失函数来测量网络的分类误差。在l2层中使用正则化方法来降低过拟合的风险,并且将正则化系数设置为0.04。训练中的学习率设置为0.01,衰减率为0.9995,最大迭代次数为30000次。
特定被试模型是通过迁移学习技术,即使用部分特定被试的数据集来调整通用模型。
深度学习模型往往需要大量的数据来进行训练。该研究中的模型自适应是基于通用ms-cnn模型的微调。在保留模型结构的情况下,使用除了输出层以外的非特定被试的参数来初始化特定被试模型。输出层的参数则由随机值初始化,并使用特定被试的数据进行训练。使用反向传播算法进行了30000次迭代,该算法使用自适应矩阵估计来优化网络参数。
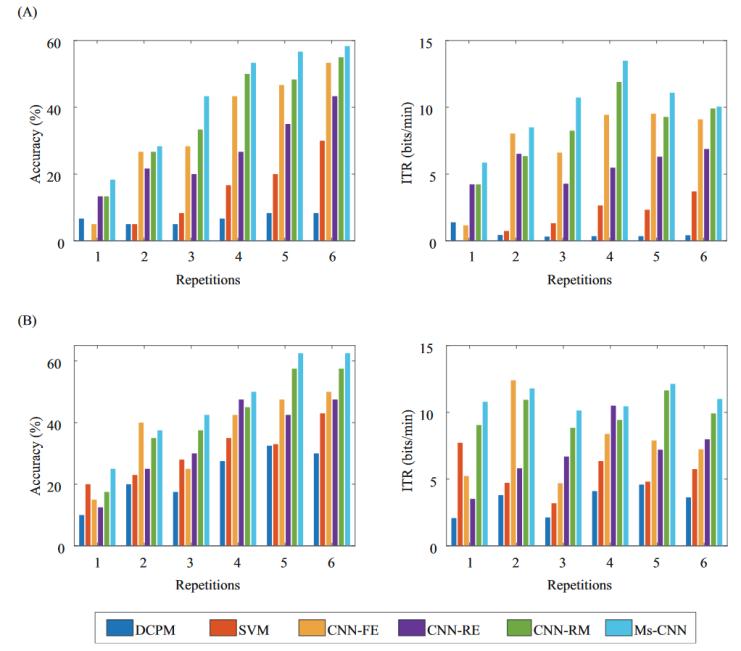 图2 (a)为非特定被试条件下,各模型在1-6次重复下的平均准确率和itr,(b)为特定被试条件下,各模型在1-6次重复下的平均准确率和itr。
图2 (a)为非特定被试条件下,各模型在1-6次重复下的平均准确率和itr,(b)为特定被试条件下,各模型在1-6次重复下的平均准确率和itr。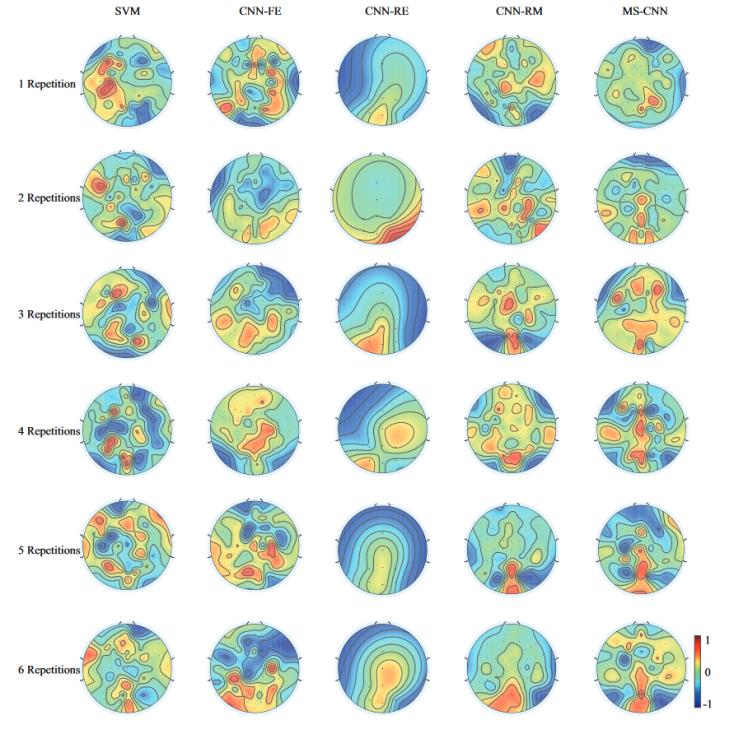
为了评估ms-cnn模型的性能,将它与五个具有代表性的模型(dcpm、svm、cnn-fe、cnn-re和cnn-rm)进行了比较。其中,dcpm是一种鲁棒性强、泛化能力强的erp分类算法,适用于小样本的情况,可以有效减少训练时间。svm是一种经典的机器学习模型。cnn-fe、cnn-re和cnn-rm是第一个成功的用于p300检测的深度学习模型。
如表2所示,ms-cnn模型的识别精度随着重复次数的增加而提高,个别被试在重复6次的情况下准确率高达100%和90%;而itr则是先提高后下降,并在4次重复的情况下达到了最高。如图1所示,ms-cnn相较于其他模型,在相同重复次数下都有着较高的准确率和itr。
图3能够更加直观的判断不同电极对于p300检测的重要性,其中红色表示该位置点击具有较高的权重,即在检测p300中具有更高的判别能力。随着重复次数的增加,高权重电极所在位置变得相对密集。
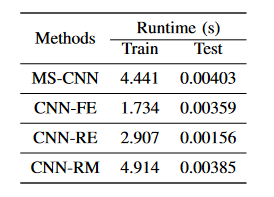
与非特定被试模型的结果类似,特定被试模型的识别精度也随着重复次数增加而上升。同样,ms-cnn在相同重复次数下,相较于其他集中模型有着更高的准确率和itr。同时,表2中展示了不同模型的运行时间比较。其中,训练时间表示训练模型所需的时间,测试时间表示识别字符所需的时间。ms-cnn在较优的性能下,与其他模型的测试时间差距也在可接受范围内。
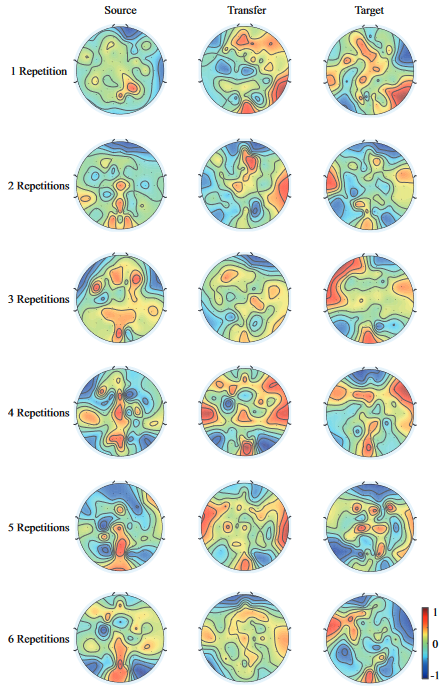
如图4所示,迁移学习增强了源域和目标域之间的相似性。对于p300检测,在迁移学习后,源域和目标域在枕叶和顶叶区域都具有明显的特征,源域的权重也具有了目标域的一些特征信息。
ms-cnn模型中使用了并行的多尺度卷积核,能够提取不同尺度的时间信息。同时实验中使用了迁移学习和数据增强来减少数据量不足以及类别数量不平衡所带来的影响。虽然较一些传统p300检测算法有着更好的性能,但在检测精度上还有很大的进步空间。
撰稿人:张嘉俊
审稿人:王斐






