 892
892
 0
0
 2023-02-26
2023-02-26
 2023-02-26
2023-02-26
这篇论文来自于2021年ieee transactions on affective computing,“contrastive learning of subject-invariant eeg representations for cross-subject emotion recognition”[1]。与其它深度学习方法研究eeg论文不同,这篇论文采用了对比学习的方法进行情感分析。该文章没有关注于对受试者的跨域问题用domain adaptation或者是domain generalization,而是使用inter-subject correlation来开发跨受试者的情绪识别方法,用对比学习来实现受试者间对齐的时空表征,从而构建主体不变的情绪表征。(如果对clip[2]等对比学习模型有了解的话,理解clisa模型还是很容易的)

eeg(脑电信号)具有可靠的信息价值,提供了一种更直接和客观的情绪反应的测量,不能轻易地伪装或有意识地抑制。与fmri(磁共振)和meg(脑磁图)等其他神经成像技术相比,eeg在现实应用中相对便携和低成本。 然而,情绪相关脑电图信号的受试者间变异性仍然对基于脑电图的情绪识别的实际应用提出了巨大的挑战。例如,在广泛使用的上交的seed数据集上,使用一个已经训练好的通用的mlp,跨受试者情感识别的准确率可以降低至 58%。相比之下,在相同的分类器下,同一受试者的情绪识别则可以达到96%的高准确率。(注:也就是说出现了跨受试者间或者跨域的问题,使得分类精确度下降。)
跨受试者中情绪识别表现的下降可以由多个因素导致(注:比如贴片贴的的位置有偏差,这个受试者今天没睡好等等)的个体情绪表征的个体差异来解释。尽管如此,情绪表征的受试者不变性在心理学和神经科学领域也得到了很好的记录。先前的 fmri 和 eeg 研究已经确定了跨受试者之间不同情绪的不同和稳定的神经表征,这表明了开发跨学科情绪识别算法的可能性。
为了解决受试者间变异性的问题,研究人员将domain adaptation(da)和domain generalization(dg)方法应用于跨受试者情绪识别。da 的目的是最小化源域(即训练对象)和目标域(即测试对象)的数据分布之间的差异。这些方法必须在训练过程中访问来自目标域的数据来测量数据的差异。然而,dg 从源域中找到域不变表示。与 da 相比,它不需要访问测试对象数据,因此在现实应用中是首选。最近,da 和 dg 方法都在 seed 数据集相当的结果。这些方法的成功表明了在情绪识别中找到受试者不变的 eeg 表示的可能性。跨受试者情感识别方法主要是从机器学习的角度出发,关注如何最小化域之间的差异,出发点不是心理学和神经科学,对人类情感处理的神经科学基础的考虑非常有限。
新兴的 inter-subject correlation(isc)的神经科学研究可以为探索主体不变情绪表征和开发跨主体情绪识别方法提供一个新的视角。isc 最初旨在研究对自然视觉场景的感知,其重点是受试者在感知相同刺激时之间的神经活动(如 eeg)的同步。从这种受试者间的角度来看,isc 的时间、空间和光谱模式可以揭示对电影和叙事等自然刺激下的神经信息处理机制。在情绪领域,几项开创性的研究表明,一组观看带有同样感情色彩的视频的受试者的脑电图信号的 isc 可以反映他们的群体水平的偏好等。这些发现表明,受试者间共享的刺激特异性eeg 反应可以为区分不同的情绪状态提供有价值的信息。 更重要的是,共享的 eeg 反应的有效性为构建受试者不变的情绪表征提供了关键的神经科学证据。该篇论文提出了一种数据驱动的方法,用对比学习来实现受试者间对齐,也就是clisa 模型。受 isc 的神经科学观察启发,clisa 基于这样的假设,即当受试者接受相同部分的情绪刺激时(例如同样感情色彩的视频),他们的神经活动处于相似的状态。基于这一基本思想,提出通过对齐类似心理活动背后的表征来学习eeg 的受试者不变空间。
clisa由两部分组成,对比学习模块和预测模块,通俗点讲就是对比学习模块编码然后预测模块分类。在对比学习过程中,由四部分组成:采样(data sampler)、编码(base encoder)、投影(projector)、损失(contrastive loss)。在预测过程中,使用对比学习学习到的表征来识别 eeg 的情绪标签。
在预测过程中,clisa 使用训练好的基编码器对齐不同受试者的表征,然后从这些表征中提取预测特征进行情绪识别。 这里,clisa 将预测过程中的数据表示为 xpred 以及他们的标签 y。标签 y 是一个分类变量。例如,如果有三个情绪类别,y 可以取三个值:0、1或2。需要预测每个样本 y 的情绪类别从经过训练的基编码器提供的输入 xpred 中提取。
该模型的参数在所有个体之间是共享的,这里假设可以找到一种个体共用的变换方式,使得所有个体在变换后能够实现功能状态“对齐”。因此,训练个体上得到的模型参数应当可以泛化到其他测试个体,无需在测试个体上调优。
在上述过程实现个体的功能状态对齐后,该方法将基础编码器输出的表征用于后续的情绪状态识别任务。具体来说,该方法对基础编码器的输出提取情绪识别中常用的微分熵特征,对特征做归一化和平滑后输入一个三层的多层感知机分类器,输出情绪预测标签。模型的整体训练流程如图1。
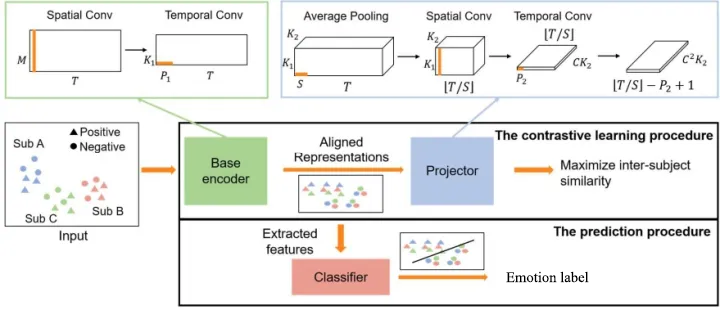 图1. clisa 的结构
图1. clisa 的结构
clisa 方法的基本思想是希望找到对脑电信号的一种变换,使得在变换后的空间内,每个个体处于相似功能状态下的脑电表征较为接近,在不同功能状态下的脑电表征距离更远。这样不同个体的脑电表征就能被较好地匹配起来,模型在这些个体上提取的共性表征应当能更好地迁移到其他个体。
那么如何定义“相似”的功能状态?在情绪诱发实验中,很多研究采用了情绪影片诱发的形式。人们在观看相同情绪影片、接受相同的视觉听觉输入时,自然就处于“相似”的功能状态。因此,在对比学习中,clisa 方法的优化目标就是使得不同个体在接受相同影片刺激时的脑电表征尽量相似。
在对比学习过程中,clisa 首先采样生成一个包含几对 eeg 片段的 minibatch 用于训练。接下来,基编码器先使用空间卷积再时间卷积对这些 minibatch 片段进行处理,目的是将数据从单个受试者转换为受试者间对齐表示。然后投影将表示形式映射到另一个潜在空间来计算它们的相似性。(原文称想法的灵感来自于 simclr 框架[3])同时,基编码器和投影的参数被优化,以最小化对比损失。 具体的对比学习策略如图2。每个批次(batch)采样两个个体的样本进行训练,一轮(epoch)训练中遍历所有的训练个体配对。
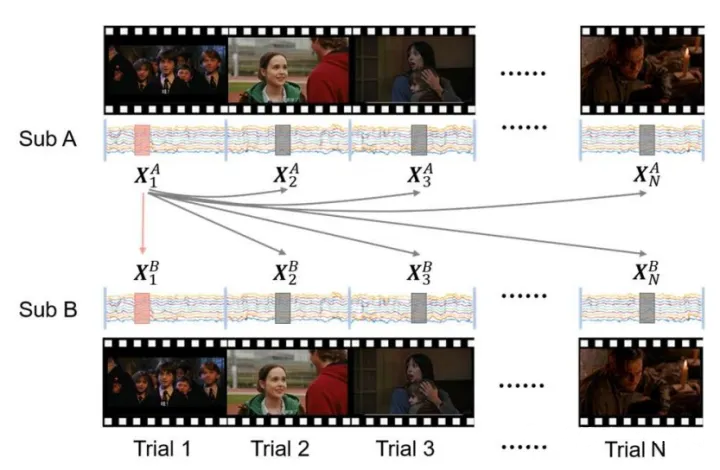 图 2. 数据采样器的说明。在一个小批中,给定一个样本 x1a ,样本x1b 与它形成一个正对,而其他样本与 x1a形成一个负对。该模型将最大限度地提高正对表示与负对表示的相似性。
图 2. 数据采样器的说明。在一个小批中,给定一个样本 x1a ,样本x1b 与它形成一个正对,而其他样本与 x1a形成一个负对。该模型将最大限度地提高正对表示与负对表示的相似性。
在对比学习中,对脑电信号做变换的模型包含两个模块:基础编码器(base encoder)和投影器(projector)(图3)。基础编码器包含一个空域卷积层和一个时域卷积层,分别对空域通道间进行线性组合和对时域信号做滤波。投影器包含平均池化、空域卷积和时域卷积层。模型的设计参考了eegnet网络架构。投影器最后输出的表征用于计算样本间的相似性。
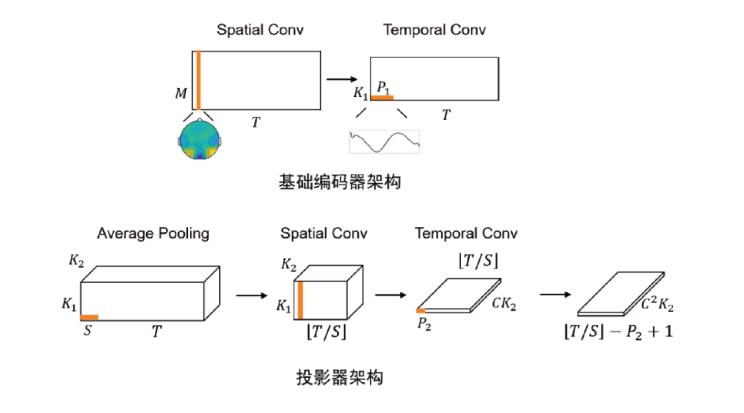 图3. clisa模型基础编码器和投影器架构
图3. clisa模型基础编码器和投影器架构
考虑到 eeg 情绪识别中的数据量有限,机器学习模型倾向于过度拟合高维表征。为了获得情绪识别的低维相关表示,clisa 从经过训练的基础编码器提供的输入 xpred ,并从中提取了广泛使用的差分熵(de)特征。(注:可能受到clip和广泛使用的大规模预训练影响,因为clip的4亿张图片文本对的海量数据弱化了overfitting的问题。)
 图4. clisa 的伪代码
图4. clisa 的伪代码
clisa方法的有效性在两个情绪状态识别的数据集上得到了验证。一个是上海交通大学吕宝粮课题组采集的seed数据集,该数据集采集了15名被试观看情绪影片时的62导脑电数据,包含积极、中性和消极三种情绪。另一个是清华大学张丹课题组采集的thu-ep(the tsinghua university emotional profile dataset)数据集,该数据集采集了80名被试在观看情绪影片时的32导脑电数据,包含九种不同的情绪类别(愤怒、恶心、恐惧、悲伤、娱悦、激励、高兴、温情、中性)。
该工作对算法的有效性进行了两种测试。第一种采取跨被试的交叉验证方法,即将被试n等分,每次取一份被试做验证,其他被试做训练。第二种被称为泛化性测试,在跨被试的基础上,只用训练被试的一部分情绪诱发影片对应的脑电数据做训练,用验证被试的另一部分情绪诱发影片对应的脑电数据做验证。这样可以检验模型在新的情绪刺激上的泛化性。两种测试方法的示意图如图5。
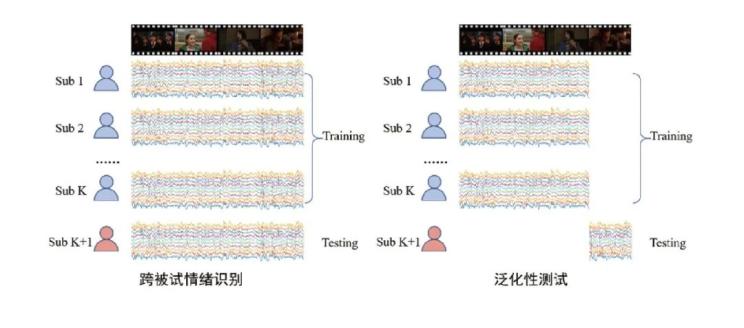 图5. 两种测试范式示意图
图5. 两种测试范式示意图
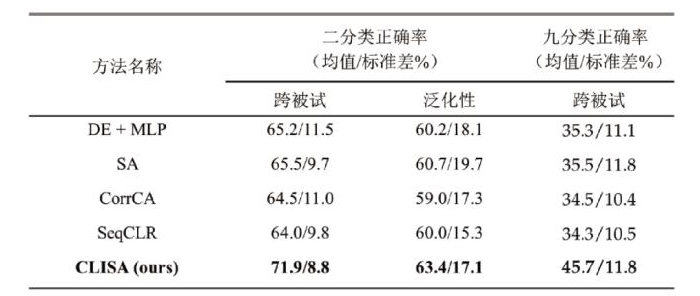
该工作在 thu-ep 数据集上做了二分类和九分类两种任务,其中二分类任务将四种消极情绪作为一类,四种积极情绪作为另一类。模型表现如表1。文中将模型与几种有代表性的方法进行对比,其中 de mlp 是直接从脑电数据中提de特征,做归一化和平滑后输入多层感知机分类的结果。sa 是迁移学习中常用的子空间对齐(subspace alignment)方法。corrca 是提取被试共性表征的常用方法。seqclr 是采用经典对比学习策略的方法。相较于其它方法,clisa 方法在几个任务上均达到了最优。
表1. 模型在thu-ep数据集上的表现
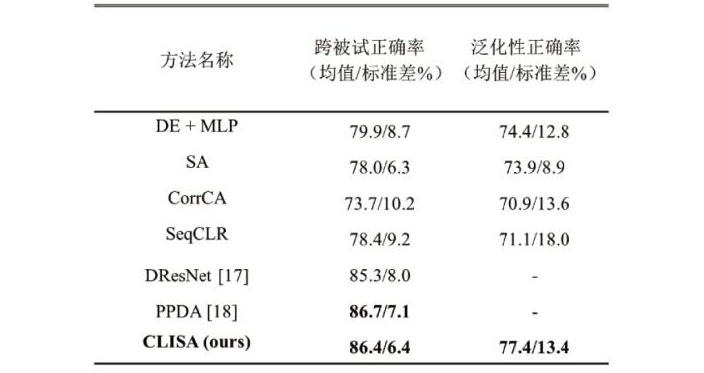
在seed数据集的情绪三分类任务上,clisa模型也超过了文中实现的其他对比模型,且与当前最优模型dresnet和ppda报告的结果相当。
表2. 模型在seed数据集上的表现
得益于文中基础编码器的设计,该工作进一步分析了对情绪分类重要的脑电空域滤波器和时域滤波器模式(图6)。该工作用积分梯度方法找到多层感知机中对情绪分类最重要的特征,可视化该特征在基础编码器中对应的空域卷积核和时域卷积核模式,发现对积极、消极和中性情绪重要的特征在空域模式上有一定的相似性,而在频域响应上则有较大差异。
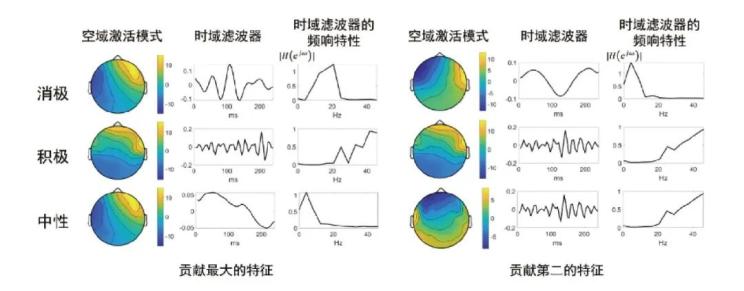
图6. 重要特征的空域模式与时频域模式可视化(seed数据集)
与现有的跨学科情绪识别方法相比,clisa 模型有几个突出的特征。首先,学习策略利用了数据的时间对齐信息,即这两段数据对应于同一视频段。因此,对比学习策略可以匹配不同的受试者更精细规模的数据。由于 dresnet、ppda 等主流 da 方法大多基于域分类器,它们只能大致匹配来自不同受试者的总体数据分布。其次, clisa 以 eeg 时间序列为输入,实现了受试者对齐,而 dresnet,ppdaz 和大多数现有的跨学科方法,使用提取的特征作为输入(注:如均值、方差、偏态、峰度、功率)。为了有效地处理eeg 时间序列,clisa 采用基于 cnn 的结构对 eeg 时间序列进行处理,结合空间维度。相比之下,以前的方法通常使用 mlp 的 dresnet 或 lstm 的ppda 用于受试者不变性学习和情绪分类。clisa 证明了在 eeg 时间序列作为输入在受试者之间找到一个共同表征空间的可能性。第三, clisa 可以在不访问新用户的数据的情况下,开始直接识别新用户的情绪,并通过输入更多的数据来提高性能自适应特征归一化。相比之下,大多数 da 方法需要来自测试对象的大量数据来适应。因此, clisa 可以提高情绪识别系统的实用性(注:准备 clip 化)。
此外文章实验部分,离散的情绪类别表现出情绪特异性的空间和时间模式。一方面,从 eeg 空间活动的角度来看,离散的情绪类别比情感维度具有更明显的神经表征。离散情绪类别背后的不同网络活动也在 fmri 研究中得到了很好的记录。另一方面,对于离散情绪类别和效价维度的时间模式都是可区分的。进一步的研究可以更深入地研究 eeg 下情绪的动态神经活动。
论文作者还指出高频响应(>20 hz)的积极情绪中,thu-ep 和 seed 数据集相一致。 但消极情绪的空间激活主要集中在 seed 数据集的更前区域,而 thu-ep 数据集的更后区域。作者认为这种差异可能是由于每个数据集的特定响应需要进一步的研究。还有一些需要注意的局限性。首先,clisa 模型使用的是利用年轻人的 eeg 数据(thu-ep 数据集平均年龄 = 20.16 岁,seed数据集平均年龄 = 23.27 岁)。由于年龄在情绪处理中起着重要的作用,需要进一步的研究,包括不同年龄范围的受试者,以建立一个更广义的模型。其次,虽然基编码器的结构可能具有神经生理学意义,但对投影可能的神经生理学意义是有限的。进一步的研究有望开发出一种更受神经生理学启发的投影仪,它可以提高整个网络架构的可解释性(注:本人觉得可以去掉映射)。最后,由于 clisa 的目标是区分不同的情绪类别,因此论文的研究作者他们可能没有充分揭示不同情绪类别之间共享的时空模式。为了更好地理解情绪处理的神经机制,应进一步研究确定情绪类别的共享和可区分时空模式。
撰稿人:陈宗楠
指导老师:潘家辉
参考资料:
[1] shen x, liu x, hu x, et al. contrastive learning of subject-invariant eeg representations for cross-subject emotion recognition[j]. ieee transactions on affective computing, 2022.
[2] radford a, kim j w, hallacy c, et al. learning transferable visual models from natural language supervision[c]//international conference on machine learning. pmlr, 2021: 8748-8763.
[3] chen t, kornblith s, norouzi m, et al. a simple framework for contrastive learning of visual representations[c]//international conference on machine learning. pmlr, 2020: 1597-1607.
[4]
[5]






